近期,数据库领域的顶级学术会议 ICDE 2023 在迪斯尼主题公园的故乡 - 美国的安纳海姆(Anaheim)举办。由 OpenMLDB 开源社区和新加坡科技设计大学(Singapore University of Technology and Design)联合完成的研究工作在 ICDE 2023 上作为工业界的常规论文发表。该项研究工作增强了 OpenMLDB 的流式特征计算能力,对其中的关键操作 Interval Join 进行了深度优化,取得了比目前工业界普遍使用的算法高达数量级的吞吐和延迟优化。基于该优化算法,克服了流式计算在实时机器学习领域所遇到的性能瓶颈,可以支持在金融、风控、推荐等领域的毫秒级实时流式特征计算的需求。其论文预印版可在此链接阅读:Scalable Online Interval Join on Modern Multicore Processors in OpenMLDB



OpenMLDB 作为一个线上线下一致的实时特征计算平台,被广泛应用于如反欺诈、风控、实时推荐等场景。在本次的研究工作中,双方合作对基于 OpenMLDB 进行流式特征的计算能力进行了深度优化。特别的,我们关注其中的性能瓶颈,即 Interval Join 操作。下图为 Interval Join 的示意图。其基于数据流 S,定义一个往前两秒的时间窗口,对数据流 R 上在对应时间窗口内的数据进行 JOIN 或者聚合操作,完成需要的特征计算逻辑。该操作在 Flink 中即为 Interval Join,在 OpenMLDB 中是通过 WINDOW UNION 语法进行副表多行聚合特征的开发,或者也被称为 point-in-time join/aggregation。
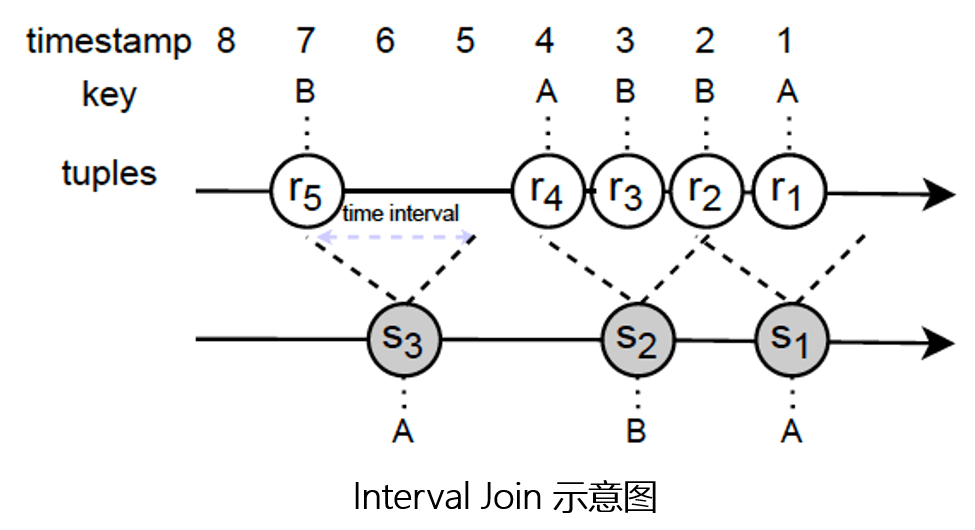
Interval Join 在现有的工业界流式处理系统中,一般使用 key-partitioned based join 算法,简称为 Key-OIJ。比如在工业界中普遍使用的流式计算框架 Flink,即使用了 Key-OIJ 的算法实现 Interval Join 的计算任务。此种算法对于一个 buffer 内的 R 和 S 做 partition,然后对于在相同 partition 内的数据再进行 join 或者聚合操作。在此次研究工作中,我们发现 Key-OIJ 在很多真实世界的工作负载中存在严重的性能问题。主要总结为:
- 工作负载不平衡和数据倾斜。当 key 的数目较少时(甚至如 key 的数量小于线程数量),非常容易出现数据倾斜的问题,从而导致整体系统的效率大幅下降。
- 当存在时间上的重叠窗口时,该算法会带来大量的重复计算,导致大窗口下整体计算效率低下。
- 由于数据无序,导致了整个计算过程的大量数据扫描;并且需要缓存更多的数据以保证结果的正确性。
在实时机器学习领域,实时特征计算一般对性能的需求在毫秒级别。使用 Key-OIJ 算法进行线上实时计算,很可能会因为高延迟而无法满足业务需求。因此,我们需要对该算法进行进一步的优化,以满足实时机器学习的需求。
为了克服以上 Key-OIJ 算法存在的问题,优化 Interval Join 的性能,我们在 OpenMLDB 的现有算法基础上,提出了一个全新的算法,称为 Scalable Online Interval Join(Scale-OIJ)。该算法针对此类工作负载优化,基于 OpenMLDB 的核心数据结构 - 双层跳表,设计了一个支持高效率单写多读(Single-Writer-Multiple-Reader index,即 SWMR)优化的索引。如下图显示了该核心数据结构和 SWMR 机制。第一次跳表维护键值到第二次跳表的映射关系;第二次跳表维护时间戳到数据行的映射关系,通过双层跳表的数据结构,可以以 log(N) 的时间复杂度,定位到需要的窗口数据,避免了如 Key-OIJ 算法中的大量数据扫描。通过支持单写多读的无锁并行数据结构,可以更加轻量的在多线程间共享数据。
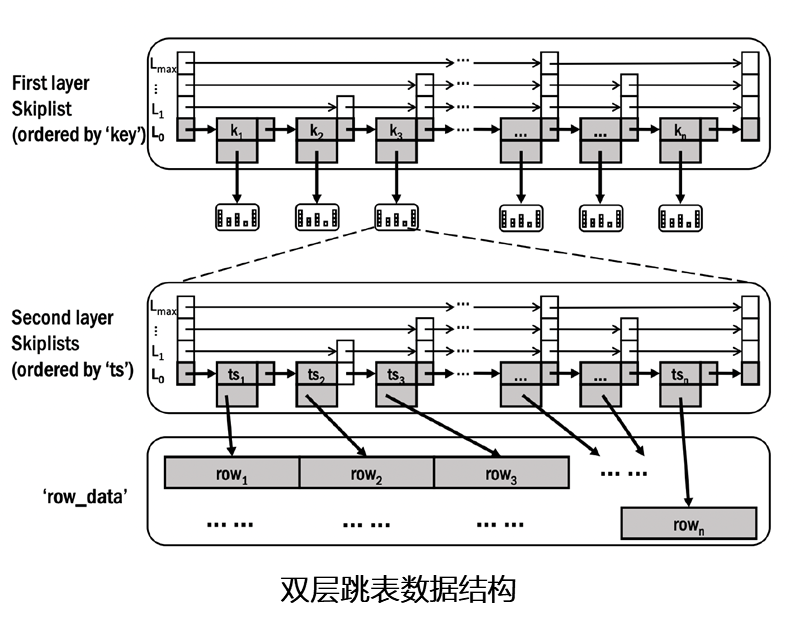
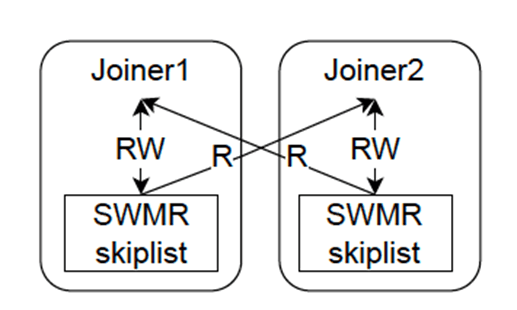
除了基于双层跳表的核心数据结构,我们还引入了更多的优化技术。
- 动态调度:通过分析实时数据流的分布情况,动态调整 partition 的策略,使得数据可以更均匀地分布到所有线程上,避免了工作负载不平衡和数据倾斜。基于单写多读的数据结构,不同线程之间可以共享数据,协同对同一个 key 进行处理,即使当 key 的数目较少时,所有线程仍然可以保持较高的稳定的 CPU 利用率。
- 增量聚合:真实数据集中,会出现大量的窗口重叠的情况,很大地浪费了计算资源。通过利用之前计算的结果,增量地更新当前计算,从而避免了重复的数据扫描和计算。当窗口很大的情况下,极大地减少了整体的数据访问和计算。
基于以上的优化,我们对 Scale-OIJ 算法进行了系统性的评估。我们使用了三个具备不同特性的真实世界数据集进行测试,测试数据集和实验结果显示如下。可以看到,在三个不同的数据集下,我们设计的 Scale-OIJ 算法比现有的 Key-OIJ 算法均有大幅的提升:在吞吐方面,有多达 24 倍的提升;在延迟方面,最多缩短了 99% 的延迟。
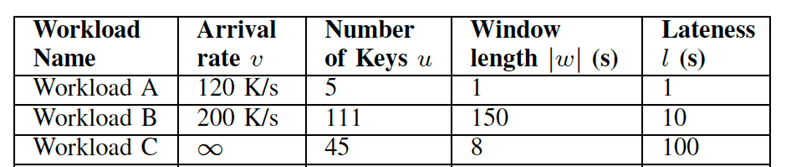
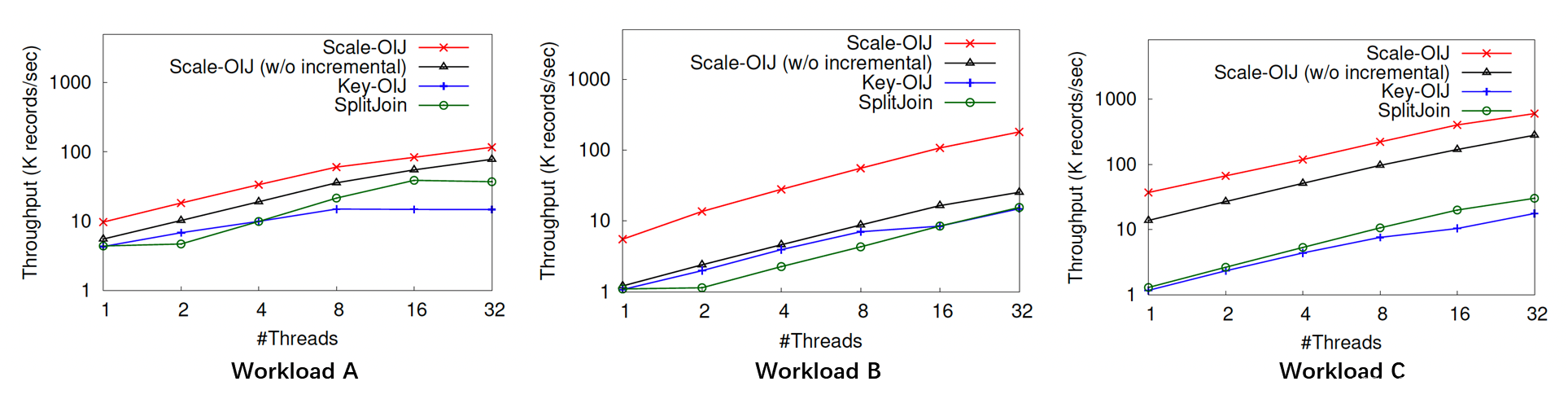
目前,该 paper 提出的 Scale-OIJ 算法已经和 OpenMLDB 进行了部分整合。未来,我们将完成最终的工程化整合,为流式特征在 OpenMLDB 的实时处理提供进一步的性能优化。我们也欢迎社区内的开发者和我们进行前沿的学术合作,共同打造 OpenMLDB 在技术上的领先性。
扫描以下二维码加入我们的社区技术讨论群

参考资料
- ICDE 论文原文:https://intellistream.github.io/downloads/papers/Zhang-2023-OIJ-OpenMLDB_CR.pdf
- OpenMLDB 的核心数据结构:实时引擎核心数据结构和优化解析
- OpenMLDB 内基于 WINDOW UNION 语法构造副表多行聚合特征:https://openmldb.ai/docs/zh/main/tutorial/tutorial_sql_2.html#id3
- OpenMLDB 产品文档:https://openmldb.ai/docs/zh/main/
- OpenMLDB GitHub: https://github.com/4paradigm/OpenMLDB